
Maskinlæring, som er en del af området kunstig intelligens, har en del forskellige programmeringsmæssige metoder, men fælles for dem alle er at de som udgangspunkt kræver megen maskinkraft for at kunne gennemføres. Derfor indeholder mange eksempler på ML en ekstern dataindsamling, en datatransmission og en central databehandling. Det er sikkert fint for de virksomheder, der ønsker at være i besiddelse af en skrækkelig masse data, men knapt så fint for belastningen på internettet – forestil dig alle de data, der skal sendes hvis hele vores bilpark skal være selvkørende. Og heller ikke så fint for vores egen sårbarhed overfor systemer, der indeholder en masse data om os.
Men der er nye metoder på vej (Og her tænker jeg ikke bare på vores egen Sladrehank/Familie, som på ML området er ganske simpel): Arduino er lille computer på størrelse med en tændstikæske og nu kan man afvikle TinyML på dem og på lignende små processorer, fx STM32. Og med Edge Impulse er det også blevet nemmere at definere dine ML algoritmer. Du kan se et eksempel her (hvor en lille, strømmæssigt billig, enhed indsamler og genkender lyde, så den kun skal sende antal eller ja/nej i stedet for at sende hele lydbilledet til en central computer.
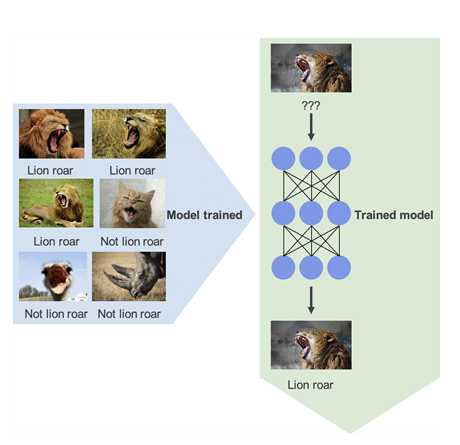
Men selv om det forekommer smartest at behandle data ved kilden, så kan det jo godt være, at der er så mange interesser, der er interesserede i centraliseringen, at der bliver udviklet mest på den type værktøjer og systemer.